BlitzNet: A Real-Time Deep Network for Scene Understanding

롤이란 게임을 시작했을 때 처음 해본 캐릭터가 블리츠크랭크였습니다. 이번에도 블로그 첫 글을 블리츠넷으로 해볼 생각입니다. 다들 처음 게임을 할 때 처음부터 잘 할 수 없듯이 처음 써보는 글이라 많이 부족할 것으로 예상이 됩니다. 오류나 질문이 있으시다면 편하게 댓글 달아주세요:)
Abstract
- BlitzNet은 Object Detection과 Semantic Segmentation을 합친(jointly) 모델이다.
- real-time computations와 computational gain을 얻을 수 있다(빠르고 계산에 효율적이다).
- Object Detection과 Semantic Segmentation의 장점을 활용하여 정확도를 높였다.
- VOC, COCO dataset을 통해 실험하였고, SOTA(state-of-the-art) 성능을 보여준다.
1. Introduction
Object Detection과 Semantic Segmentation은 컴퓨터 비전의 기본적인 영상 처리 방법이다. Object Detection은 이미지의 모든 물체들을 카테고리별로 식별하고 박스로 위치를 나타낸다. Semantic Segmentation은 미세한 크기로 작동한다. 각 pixel마다 class label을 부여하여 각 다른 색으로 칠한다.

Segmentation의 성능이 좋으면 detection도 성능이 좋을 것으로 모두가 예상할 수 있다. Detection의 경우 ground-truth segmentation가 있으면 detection 하기에 용이할 것이고, segmentation의 경우도 detection 한 boxes가 있다면 도움이 될 것이다. 이 논문에서 핵심이 되는 목표는 이 두 문제를 동시에 처리하는 것이다.
CNN기반의 모델이며, Object Detection을 할 때 real-time speed를 위해 SSD(Single Shot Dection) 모델을 사용하였다. SSD에서는 다양한 사이즈의 feature map을 사용하였는데 이것은 deconvolutional layers와 skip and residual connections을 추가하면서 성능이 향상되었다. 특히 deconvoluional layers는 segmentation의 정확도를 향상시켰다.
2. Related Work
Object Detection: R-CNN은 성능은 좋지만, speed가 느렸고, R-FCN은 region-based mechanism이 object detection에 한정된 방법이어서 segmentation과 함께 사용하기 어려웠다. 결국에는 SSD를 선택하게 되었고 이 모델은 SOTA object detector로 정확도와 속도 모두 뛰어나다. SSD에 대한 자세한 설명은 추후에 올릴 예정이다.
Semantic Segmentation: Deconvolutional architecture는 feature map의 resolution을 증가시키며 input image와 같은 크기로 output이 나와야 하는 segmantation을 할 때 upsample 용도로 많이 사용된다. 하지만 이것은 object detection을 할 때도 유용하게 사용될 것이다.
Joint Semantic Segmentation and Object Detection: 두 모델을 합치는 실험은 이전부터 있었는데, 두 모델을 각각 따로 학습을 시키는 것보다는 동시에 시키는 것이 더 좋다는 결론이 나왔다. 최근에 UberNet이라는 두 기능을 탑재한 single deep neural network가 나왔다. Detection 부분은 Faster R-CNN을 이용하였기 때문에 fully-convolutional도 아니고 real-time도 아니었다. 최근에는 VGG16으로 image features를 계산하고 두 개의 sub-network를 이용하여 detection과 segmentation을 하는 방법이 나왔다. 논문의 필자는 이러한 방법에 영감을 받아 training을 단순화시키고, feature를 공유하며, 속도가 빠르고, weights(가중치)를 공유하는 multi-task model을 만들었다.
3. Scene Understanding with BlitzNet
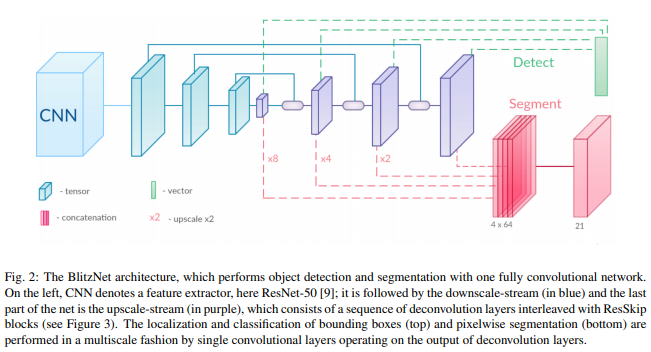
1. Global View of the Pipeline
먼저 input image는 CNN을 거치면서 high level feature들을 뽑아낸다. 여기서는 ResNet-50을 feature encoder로 사용하였다. Feature map들의 크기는 multi-scale로 작아졌다 커지게 된다. 이 이유는 SSD는 다양한 크기의 feature map에서 정보를 받아 사용하기 때문이다. Feture map의 크기를 키울 때는 앞서 말했던 deconvolutional layer가 사용된다. 크기를 다시 키워서 segmentation에 사용하기 위해서 이다. 마지막에 있는 single convolutional layer는 각각 detection과 segementation을 담당한다.
2. SSD and Downscale Stream
SSD는 input image에 anchor box의 regular 한 grid를 tiling 한다. 이후에 CNN을 통해 이 박스들을 분류하고 각 박스의 좌표마다 정확도를 측정한다. 원래 SSD 논문에서는 base network로 VGG-16을 사용하였고, feature map의 크기를 줄여나가면서 각 feature map마다 default bounding boxes의 correction을 predict 했다. 마지막으로 예측된 bounding box가 NMS(Non-Maximum Suppression)를 거치면서 최종 output이 나오게 된다. BlitzNet 모델은 위의 Figure 2와 같은 과정을 거치며 devonvolutional layers에서 detection과 segementation을 하게 된다.
3. Deconvolution Layers and ResSkip Blocks
Semantic Segmentation에서도 정확한 위치 정보가 Object Detection과 동등하게 중요한 역할을 한다. 이러한 문제를 해결하는 방법으로 devonvolutional operation을 제안한다. High and low level features를 결합하는 것뿐만 아니라 학습을 진행하는 것에 용이하다. Object detection이나 pose estimation과 같이, 여기서도 downscale과 upscale로부터 나온 feature map들을 결합해주는 skip connections mechanism을 사용한다. 정확도를 위해 downscale and upscale로 부터 나온 feature map들을 ResSkip이라는 방법을 통해 결합한다.

들어온 feature map들은 bilinear interpolation을 통해 해당하는 skip connection 크기로 upsample 된다. 그 후에 skip connection map과 upsampled map들을 concat 한다. Concat은 그림과 같이 두 개의 feature map을 겹치는 것을 의미한다. concat을 하고 3개의 block(1x1 conv, 3x3 conv, 1x1 conv)을 거치게 된다. 마지막으로 residual connection을 통해 처음에 upsample 한 map과 더해준다.
(참고: Upscale 쪽에 화살표처럼 보이지만 순서는 왼쪽에서 오른쪽으로 가니 헷갈리지 말자)
4. Multiscale Detection and Segmentation
Object detection과 semantic segmentation은 여러 가지 key properties를 공유한다. 이 두 개는 모두 물체 주변과 물체 내부의 픽셀을 기반으로 영역별 classification이 필요하고 위치 정보를 포함하고 있는 rich features로부터 나오는 benefit이 필요하다. 두 task를 실행하는 model을 각각 따로 훈련시키지 않고, weight(가중치)를 공유하는, 한 번에 training 하는 방법을 선택했다. 이 방법은 두 task 간에 좋은 영향을 끼쳤다.
결론적으로 대부분의 weights는 공유되며 object detection은 single convolutional layer가 upscale 부분의 feature map에 있는 bounding boxes에 대한 class와 좌표를 예측한다. 유사하게 segmentation에서도 single convolutional layer가 predicting pixel label과 segmentation maps를 생성하는 데 사용된다. 이것을 달성하기 위해 upscale 부분의 모든 activations를 upscale 하여 같은 크기로 만들고 concat 하여 마지막 classification layer에 입력하였다.
5. Speeding up Non-Maximum Suppression
Anchor box의 갯수가 증가함에 따라 inference time도 크게 영향을 받는다. 왜냐하면, NMS가 잠재적으로 모든 예측된 값들에 대해 실행되기 때문이다. 게다가 sliding windows를 사용하면서 inference time이 더욱 증가하게 되었고, nms가 bottleneck이 되었고 너무 많은 박스들을 찾아내는 것을 확인할 수 있었다. 그러므로 새로운 post-processing 방법을 제안하였다. 각 class마다 score가 높은 순으로 400개의 box를 pre-select 한다. 그리고 NMS를 50개의 box만 남기도록 실행시킨다. NMS 실행 후, 모든 detection output 중에 score가 높은 200개만 나오도록 한다. 이것을 통해 계산하는 시간이 줄어들었고, 정확도에 크게 영향을 미치지 않았다.
6. Training and Loss Functions
처음에는 두 loss function을 더하여 reweighting을 하려고 했으나 눈에 띌만한 향상이 일어나지 않았다.
Segmentation은 cross-entropy loss function을 이용했고, 1x1x64 conv를 upscale 부분의 각 layer에 사용했다. 그 후에 앞서 말한 것처럼 bilinear interpolation을 통해 upscale 하고 concat을 한다. 이 결과는 class별 확률을 예측하기 위한 3x3 conv를 사용하여 class 갯수의 feature maps와 mapping 된다.
Detection을 할 때는 같은 loss fuction을 사용하며, anchor boxes로 input image에 tiling 한 것과 ground truth bounding boxes를 매칭 한 것을 통해 loss를 계산한다. Anchor box의 좌표를 보정하고 class의 확률 분포를 예측하기 위해 upscale 부분의 각 layer 마다 actiavations를 사용한다. Data augmentation은 SSD pipeline과 동일하게 photometric distortions, random crops, horizontal flips and zoom-out을 사용했다.
4. Experiments
1. Datasets and Metrics
COCO, VOC07, and VOC12 datasets를 사용하였다. 이 dataset에 대한 설명은 논문을 보면 충분히 알 수 있고 중요하지 않으니 넘어가겠다.
2. Experimental Setup
Optimization Setup: Adam alogithm을 사용하고, mini-batch size는 32로 두었다. learning rate는 0.0001이고 두 번에 걸쳐 줄어들고 factor는 10이다. Weight decay parameter는 0.0005이다.
Modeling Setup: Feature extractor로 ResNet-50을 사용하였고 down-scale과 up-scale을 하는 layer에 대해 512개의 feature maps이 나온다. Segmentation branches에서 64개의 channel을 갖는 feature map이 사용된다. BlitzNet300 모델은 input image size가 300x300이고, BlitzNet512는 input image size가 512x512이다. Stride 4와 8의 차이는 결과표에 (s4)와 (s8)로 명시할 예정이다.
3. PASCAL VOC 2007
VOC07과 VOC12를 사용하여 train 하였고 VOC07 test set으로 test 하였다. 300 모델 학습은 65K iterations 만큼 진행하였고, learning rate는 35K, 50K 이후마다 감소시켜주었다. 500모델 학습은 batch size를 16으로 해주었고, 75K 만큼 학습을 진행하고 45K, 60K 이후마다 learning rate를 감소 시켜주었다.

Table 결과를 보았을 때, BlitzNet300은 78.5 mAP를 달성하며 SSD300, YOLO와 비교했을 때 이를 뛰어넘는 성능을 보여주었다. 또한, BlitzNet512(s8)는 80.7 mAP로 R-FCN의 성능보다 좋았으며, 학습을 할 때 detection과 segmentation을 병합했을 때 성능이 더 좋아진 것을 확인할 수 있다. 또한 stride의 크기도 큰 것이 더 좋은 결과를 도출했다.
4. PASCAL VOC2012
VOC12 train-seg-aug로 학습을 하였으며, VOC12 val-seg로 test를 진행하였다. 학습은 40K step동안 진행하였고 learning rate는 25K, 35K step에 걸쳐 줄어들었다.

이 표를 보면 병합하여 학습을 시키는 것이 정확도를 개선시킨 것을 확인 할 수 있다. 논문에서는 이 이유를 feature가 공유되기 때문이라고 말하고 있다. 이것을 입증하기 위해 하나의 실험을 하였다. VOC07 train set과 VOC12 train-seg-aug를 합쳐서 학습을 시켰다. 그러므로 segmentation과 detection의 비율이 2:1이 되게 하였다.
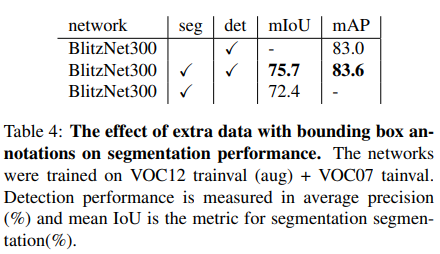
결과는 표에 있는 대로 mIoU는 3.3%, mAP는 0.6%가 상승하였다.
아래 표는 VOC12 test sever에서 결과를 도출한 것으로 BlitzNet의 mAP가 가장 높은 것을 확인할 수 있다.

5. Microsoft COCO Dataset
앞서 실험한 대로 COCO dataset을 사용하여 실험하였다. BlitzNet300은 700K iteartions 만큼 학습을 한다. Learning rate는 초기값 0.0001 에서 400K, 550K마다 감소한다.
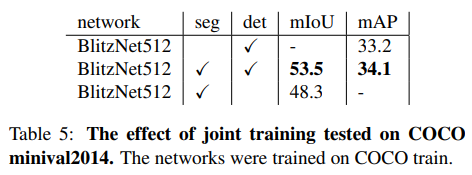
이 표는 Table 3와 같은 것을 의미하며 joint training이 어떠한 영향을 끼쳤는지 보여주는 지표이고 성능이 좋아졌음을 보여준다.
6. Inference Speed Comparison

다른 SOTA detection 모델들과 비교했을 때 BlitzNet은 mAP가 가장 높고, FPS는 SSD300이나 YOLO에 비해 느리지만 real time에 가깝기 때문에 빠르다고 볼 수 있다.
7. Study of the Network Architecture
BlitzNet은 ResSkip block을 사용한다. ResSkip의 효과를 입증하기 위해 실험을 진행하였다. 이 ResSkip block을 다른 block으로 교체를 하였다.

Table 8이 보여주는 대로 ResSkip의 결과가 가장 좋았다.
최적의 파라미터들을 위해 segmentation stream에서는 64개의 channel과 upscale-stream에서는 512개의 channel이 이용이 되었다. 이 layer의 갯수를 변경하는 실험은 진행하지 않았는데, 이 이유는 symmetric을 유지하기 위함이다. Down-scale을 할 때의 step보다 더 많이 upscale을 하거나 적게 upscale을 하면 성능이 변할 것이기 때문이다.
5. Conclusion
이 논문에서는 object detection과 semantic segmentation을 병합한 single fully-convolutional network를 소개했다. 두 task 간에 weights를 공유하면서 학습에 용이했고, real-time의 속도를 보여주었다. 정확도 측면에서도 높은 성과를 보여주었다.
2017년에 나온 논문으로 시간이 많이 지났지만 다른 모델에 비해 유명하지 않는 모델이다. 하지만 multi-tasking 모델을 이해하는 데는 도움이 될 것으로 예상되며, 공부를 하는 데에는 추천하지만 최근에 나온 더 좋은 multi-tasking 모델이 많기에 실제로 사용을 한다면 추천하지는 않는다.
첫 글이라서 부족한 점이 많을 것으로 예상됩니다. 혹시나 이상한 부분이 있다면 언제든지 댓글 남겨주세요. 질문도 환영입니다:)
'Paper Review' 카테고리의 다른 글
| [논문 리뷰] ResNet (0) | 2022.08.15 |
|---|---|
| [논문 리뷰] Positional Encoding as Spatial Inductive Bias in GANs (1) | 2021.09.07 |
| [논문 리뷰] Position, Padding and Predictions: A Deeper Look at Position Information in CNNs (0) | 2021.08.05 |
| [논문 리뷰] How Much Position Information Do Convolutional Neural Networks Encode? (2) | 2021.07.19 |
| [논문 리뷰] CoordConv (1) | 2021.07.15 |




댓글