You Only Look Once: Unified, Real-Time Object Detection
Abstract
이전 연구에서는 Classifier를 따로 만들어서 사용하는 2 Stage 모델을 흔히 사용하였다. 이 논문에서는 Box Regression과 Class의 확률 예측을 동시에 수행하는 방법을 제안한다. 하나의 Network로 진행되기 때문에 논문의 이름처럼 한 번만 모델을 거치면 위치와 Class를 모두 알 수 있게 되는 것이다. 이 모델 구조의 장점은 빠르다는 것인데, 45 FPS를 보였고, Fast YOLO의 경우 155 FPS를 보였다. 심지어 정확도 측면에서 다른 모델과 비슷한 mAP를 보였다.
1. Introduction
사람의 경우 사진을 보자마자 빠르고 정확하게 물체의 위치와 무엇이 있는지 확인할 수 있다. 사람처럼 작동하기 위해서는 빠른 속도가 중요하지만 현재 Detection 알고리즘들은 Classifier를 따로 사용하여 속도가 느려질 수 밖에 없었다. 특히 R-CNN 계열은 2 Stage가 되고, Post-processing도 진행하면서 매우 복잡하고 느린 단점이 있었다. 이를 해결하기 위해 Class와 Box를 동시에 찾아내는 모델을 설계하였고 아래 사진처럼 간단한 과정을 거치는 것을 볼 수 있다.

이렇게 설계된 모델은 3가지 장점을 갖는다.
1) 매우 빠른 속도를 갖는다.
Object Detection이라는 Regression Problem임에도 불구하고 복잡한 Pipeline을 갖지 않는다. Titan X GPU에서 45 FPS, 경량화 모델은 150 FPS의 성능을 보였다. 이뜻은 충분히 Real-time Task에 사용 가능하다는 것을 의미한다. 게다가 정확도 측면에서도 다른 모델보다 2배가량 높은 성능을 보였다.
2) 사진의 전체적인 부분을 통해 물체를 예측한다.
RPN과는 다르게 YOLO는 사진 전체를 보고 Contextual Information을 더 잘 학습한다. 이전 SOTA 모델이었던 Fast R-CNN의 경우에 뽑아낸 Region만 보았기 때문에 Background에 대한 Error가 많이 발생하였다. 하지만 YOLO는 전체를 보면서 학습했기 때문에 이러한 에러가 절반 가까이 줄었다.
3) 물체의 Representation을 학습할 때 Generalization이 잘된다.
이를 확인하기 위해 Natural Image, 일반적인 사진으로 학습을 하고 artwork와 같은 그림이나 삽화를 Test 해보았을 때, 높은 성능을 보였다. 이 뜻은 Generalization이 잘 되었다는 뜻으로 처음 보는 사진에 대해서도 잘 적용된다는 것을 알 수 있다.
2. Unified Detection
본 논문에서 Object Detection을 수행하던 여러 요소들을 하나로 통합하였다. Bounding Box와 Class를 동시에 찾으면서 입력 영상으로 부터 나온 Feature를 통해 예측하였다. YOLO는 Precision은 유지하면서 속도를 빠르게 하였고, end-to-end 학습이 가능하도록 하였다.
특이한 점은 입력 영상을 S x S grid로 나누었다는 것이다. Object의 중심이 Grid Cell에 들어가게 되면 그 Grid Cell을 이용하여 Object Detection을 진행한다. 각 Grid Cell은 B개의 Bounding Box와 각 Box들의 Confidence Score를 예측한다. 이때 Confidence는 Box에 물체가 있을 확률을 의미한다. 구하는 식은 다음과 같다.

각 Bounding Box는 5개의 예측값으로 이루어져 있는데 각각 x, y, w, h, Confidence이다. 여기서 x, y는 Box의 Center의 좌표이고, w, h는 너비와 높이이다. Confidence는 Ground truth Box와 Predicted Box의 IOU를 나타낸다.
각 Grid Cell은 C개의 조건부 확률을 구하는데, Object가 존재할 때, Class에 대한 확률이다.

Bounding Box의 갯수에 상관없이 각 Grid Cell당 하나의 Class 확률 분포를 구하게 된다. Test를 할 때에는 조건부 확률과 Confidence Score를 곱해준다. 그렇게 되면 Class별 Confidence Score가 나오게 된다. 이때 Class와 Object의 Joint Probability가 되어야하지 않나 생각이 들지만, Object가 존재해야 Class가 존재하므로 포함관계에 속한다.

이 식은 Class에 대한 확률도 포함하지만 Object에 제대로 맞게 Box를 예측했는지에 대한 정보도 함께 포함되어 있다.

1. Network Design
먼저 이 모델은 PASCAL VOC detection Dataset에 대해 실험하였다. 모델 초반의 Convolution Layer는 Feature Extractor의 역할을 하고, Fully Connected Layer는 확률과 위치 좌표를 예측하는 역할을 한다. 모델의 Architecture는 GoogLeNet에서 영감을 받았는데, 24개의 Convolution Layer와 2개의 Fully Connected Layer를 사용하였고 Inception Module 대신에 1x1의 Reduction Layer만 사용하고 3x3 Convolution을 사용하였다. 모델 구조는 아래와 같다.

또한 Fast 버전의 YOLO도 학습하였는데, 이 모델은 24개의 Conv가 아니라 9개만 사용하였고, Filter도 적게 사용되었다. PASCAL VOC Dataset에 대하여 최종 출력은 7x7x(2 * 5 + 20)이 된다.
2. Training
먼저 Convolutional Layer들을 ImageNet Dataset에 대해 Pretrain을 한다. 이때는 앞에 존재하는 20개의 Layer만 학습을 진행하였고 뒤에 Average Pooling과 Fully Connected Layer을 붙여서 Classification 모델을 만든 뒤에 학습을 진행하였다. 또한 YOLO의 특징 중 하나는 Darknet Framework를 사용한다는 점이다.
Detection을 진행하기 위해서는 20개의 Layer 이후에 4개의 Convolutional Layer와 2개의 Fully Connected Layer를 추가하였다. 또한 Input Resolution을 224x224에서 448x448로 증가시켰다. 마지막에 나오는 Layer는 물체의 확률과 위치를 모두 예측한다. Bounding Box의 Width와 Height는 입력 영상의 Width와 Height로 나누어 Normalize를 해주었고, Bounding Box의 x, y좌표를 Grid Cell 위치의 Offset으로 지정하였다. 마지막 Layer에만 Linear Layer를 사용하고 나머지 Layer는 Leaky ReLU를 사용하였다. 이때 c값은 0.1로 사용하였다.
Optimization을 쉽게 하기 위하여 sum-squared error를 사용하였다. 하지만 이는 AP를 늘리는 관점에서는 완벽하지 않은 방법이다. Localization Error와 Classification Error가 동일한 크기의 Loss가 발생하지 않기 때문인데, Loss가 클수록 그 방향으로 학습을 하려고 하기 때문이다. 대부분의 사진의 Grid Cell에는 Object가 없는 경우가 많기 때문에 Confidence Score는 대부분 0이 나오게 된다. 그래서 Object가 있는 Cell에서 생긴 Gradient가 무시될 수 있다.
이를 해결하기 위해 Bounding Box 좌표에 대한 Loss를 5배 증가하고, Object가 없는 Box의 Confidence에 대한 Loss를 0.5배 감소하였다. 또한, 큰 Box와 작은 Box는 작은 차이로 생기는 변화로 생기는 Loss 값이 다를 수 밖에 없다. 큰 박스는 작은 변화에도 Loss 변화가 크지 않지만, 작은 박스는 조금만 변해도 Loss에 큰 변화가 생기게 된다. 이를 방지하기 위해 Width와 Height를 예측할 때, 루트를 씌운 값을 예측하도록 하였다.
YOLO는 Grid Cell 당 여러개의 Bounding Box를 찾는다. 하지만 학습을 할 때는 Object당 하나의 Bounding Box만 사용돼야 하기 때문에 가장 IOU가 높은 것을 선택하여 정확한 크기와, Ratio, Class, Recall 측면에서 성능이 개선되었다.
Loss 함수는 다음과 같이 정의하였다.
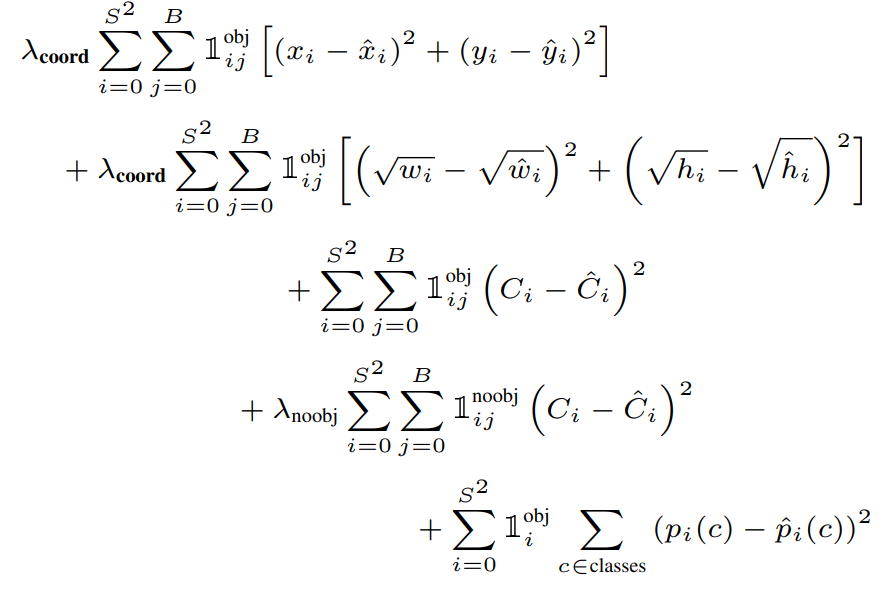
여기서 확인할 수 있는 것은 Classification의 경우 Object가 Grid Cell에 존재할 때만 포함되고, Bounding Box Coordinate Loss에 대해서는 1개의 Bounding Box만 사용되는 것을 알 수 있다.
3. Inference
YOLO는 1 Stage 모델이기 때문에 Inference Time의 경우에도 좋은 성능을 보인다. Grid Cell을 사용하면서 공간의 다양성을 확보하여 Bounding Box Prediction의 성능을 높였다. 대부분 하나의 Object가 속하는 Grid Cell이 명확하고 하나의 Bounding Box가 사용되지만 몇몇의 큰 Object나 경계 근처에 있는 Object는 여러 개의 Cell을 이용해야 Localization이 잘 될 수 있다. 이렇게 여러 Cell을 사용할 때 고정시키기 위해 NMS가 사용된다.
4. Limitation of YOLO
YOLO의 경우 Bounding Box의 공간적 제한이 존재하는데, 각 Grid Cell마다 2개의 Box와 1개의 Class만 예측할 수 있다는 것이다. 그렇기 때문에 근접해 있는 물체나, 작고 무리를 지어 다니는 물체를 찾는 것은 어렵다. 또한, Generalization이 어려운데, 새로운 사진이나 특이한 비율의 사진이 들어오면 객체를 찾기가 어렵다. Bounding Box의 크기마다 Error의 크기도 달라지는데, IOU로 인해 작은 Box일수록 작은 변화에도 Error가 커지게 된다.
3. Comparison to Other Detection Systems
대부분의 Pipeline은 입력 영상의 Feature를 추출하고, Classifer나 Localizer가 물체를 찾기 위해 사용된다. 이러한 Classifier와 Localizer들은 Sliding Window를 사용하며 Feature 전체를 보거나 특정한 영역을 확인하여 예측한다. 아래에서는 이 당시 사용되었던 성능이 우수한 모델들과 비교한다.
Deformable parts models
DPM은 Sliding Window를 이용해서 Object Detection을 하는 모델이다. DPM은 Feature Extractor, Classification Region, Prediction Bounding Box로 Pipeline을 나누었다. 하지만 YOLO는 이 모든 부분을 하나의 Network로 만들었다. 이 Network는 Feature Extraction, Bounding Box Prediction, NMS 등을 한번에 진행한다. YOLO가 DPM보다 더 빠르고, 정확하다.
R-CNN
R-CNN은 객체를 검출하기 위해 Region Proposal을 사용한다. Selective Search를 이용하여 Bounding Box가 있을만한 위치를 찾고, Convolution Layer가 Feature를 추출하고, Box의 Confidence Score와 위치를 찾아내고, NMS를 사용한다. 각 단계들은 복잡하고 독립적으로 작용한다. 따라서 속도가 느리다. YOLO는 R-CNN과 공통점도 갖고 있는데, Grid Cell이 R-CNN에서의 Region Proposal과 비슷하고, 이를 Convolution Layer에 사용한다는 점이 비슷하다. 하지만 Grid Cell의 경우 하나의 Object에 대해서 여러 Detection을 방지하기 위해 공간적인 제약이 존재한다. 또한 한 이미지당 평균적으로 98개의 Bounding Box가 생기는 반면 Selective Search는 2000개의 Proposal을 생성한다. 마지막으로 YOLO는 R-CNN의 모든 요소를 하나의 Network로 만들었고, 최적화에 성공했다.
Other Fast Detectors
Fast and Faster R-CNN 들은 R-CNN Framework에서 빠른 속도를 자랑하는 모델이지만 YOLO보다 느렸고, DPM의 경우도 속도를 높이기 위해 여러 노력을 했지만 YOLO의 속도를 따라올 수는 없었다. 또한, Class가 여러개이기 때문에 다양한 물체를 탐지할 수 있고, 학습할 수 있다.
Deep MultiBox
R-CNN과는 다르게 Deep MultiBox는 Region Proposal을 CNN으로 뽑아낸다. MultiBox는 Single Object와 Single Class에 대해 Object Detection을 할 수 있지만, 일반적인 Object Detection은 불가능하다. YOLO와 MultiBox 모두 Convolution Layer를 사용하지만 YOLO는 완전한 Object Detection System이다.
OverFeat
OverFeat은 CNN을 이용하여 Localization을 진행한 모델이다. OverFeat은 Localization을 효율적으로 수행하지만 Detection이 아니라 Localization에 초점이 맞춰져있다. DPM과 비슷하게 Local Information을 주로 본다. 하지만 YOLO는 Global Information을 사용할 수 있다.
MultiGrasp
YOLO는 grasp detection과 비슷하다고 말할 수 있다. Grid Cell 방법도 MultiGrasp System을 참고해서 만든 것이다. 하지만 grasp detection은 object detection보다 단순하고 쉽다. MultiGrasp은 하나의 graspable region을 찾으면 되지만, object detection은 object의 크기, 위치, 경계, class를 모두 고려해야 한다. YOLO는 여러 물체와 여러 Class를 찾을 수 있다.
4. Experiments
먼저 PASCAL VOC 2007을 이용해서 다른 모델들과 YOLO의 성능을 비교한다. 또한, Error의 특징들을 확인하면서 다른 모델들과 특성을 비교한다. 실험을 통해서 YOLO가 Background로부터 생기는 False Positive를 줄인 것을 확인할 수 있다. VOC 2012에도 실험을 진행하고, 마지막으로 새로운 도메인인 artwork Dataset에 실험을 진행한다.
1. Comparison to Other Real-Time Systems
Fast YOLO의 경우 PASCAL Dataset을 사용한 모델중에 가장 빨랐고, 52.7% mAP를 달성하였다. 일반 YOLO는 63.4% mAP의 성능을 달성하였다. VGG16을 이용하여 YOLO를 학습해보았지만 정확도는 조금 올라갔지만 속도가 매우 느려졌다. Fastest DPM은 DPM에서 정확도를 포기하고 속도를 매우 높인 모델인데, 그럼에도 Real-Time까지의 속도가 나오지 않는다. R-CNN에서 R 부분을 빼도, 속도는 빨라지지만 Real-Time에 조금 못 미치는 성능을 보인다. Fast R-CNN은 mAP는 높지만 0.5 FPS로 매우 느리고, Faster R-CNN은 10 FPS로 빨라졌지만 YOLO보다 6배나 느리다.
2. VOC 2007 Error Analysis
YOLO와 다른 모델을 비교하기 위해서는 mAP 성능 뿐만 아니라 세부적인 부분을 확인할 필요가 있다. 성능을 확인하기 위해 다음과 같은 방법을 사용했는데, 각 Category마다 N개의 가장 높은 Prediction을 뽑는다. 이 Prediction이 정답인지 확인하는데, 나머지 Error는 다음과 같이 분류한다.
- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU < .5
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
아래 그림은 Class 20개에 대한 평균값을 도표로 표기한 것이다.

YOLO는 Localization의 성능이 Fast R-CNN보다 성능이 좋게 나오는 것을 확인할 수 있었다. 하지만 Background Error의 경우 YOLO가 더 낮은 것을 확인할 수 있다.
3. Combining Fast R-CNN and YOLO
YOLO가 Background Error를 줄여준다는 것을 이용하여 Fast R-CNN에 적용하여 성능 향상을 하였다. R-CNN이 예측한 모든 Bounding Box에 대해 YOLO가 Similar Box로 인식했는지 확인한다. 이렇게 해서 기존 모델은 PASCAL VOC 2007에 대해 71.8% mAP의 성능을 보였지만, YOLO와 합친 모델은 75.0% mAP로 3.2% 올랐다.
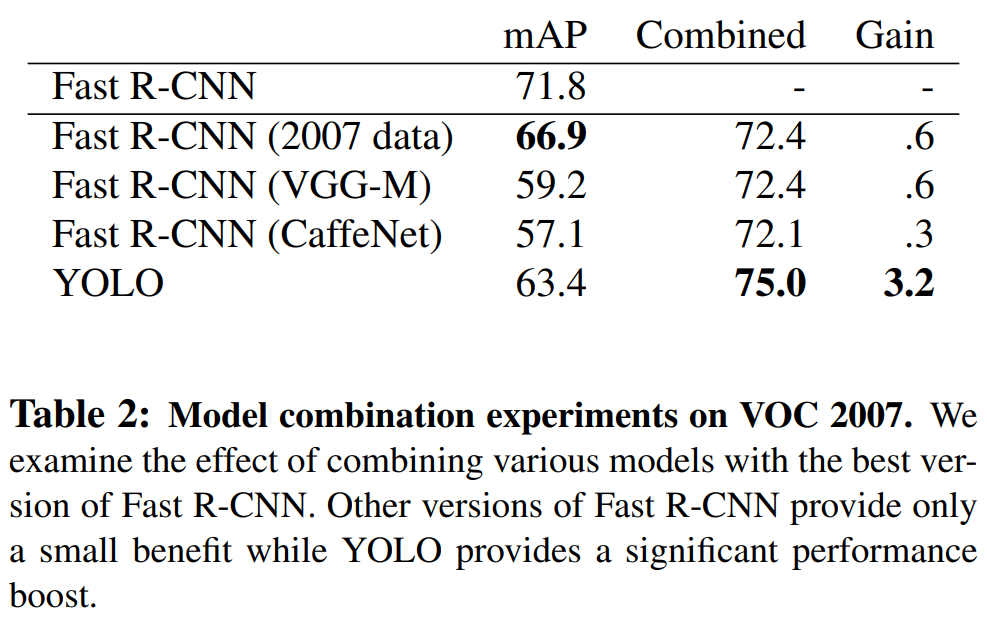
다른 모델과도 YOLO를 합쳐보았지만, 성능은 조금밖에 차이가 나지 않았다. 하지만 이렇게 됐을 때, YOLO의 장점인 속도는 다시 떨어지게 된다.
4. VOC 2012 Result
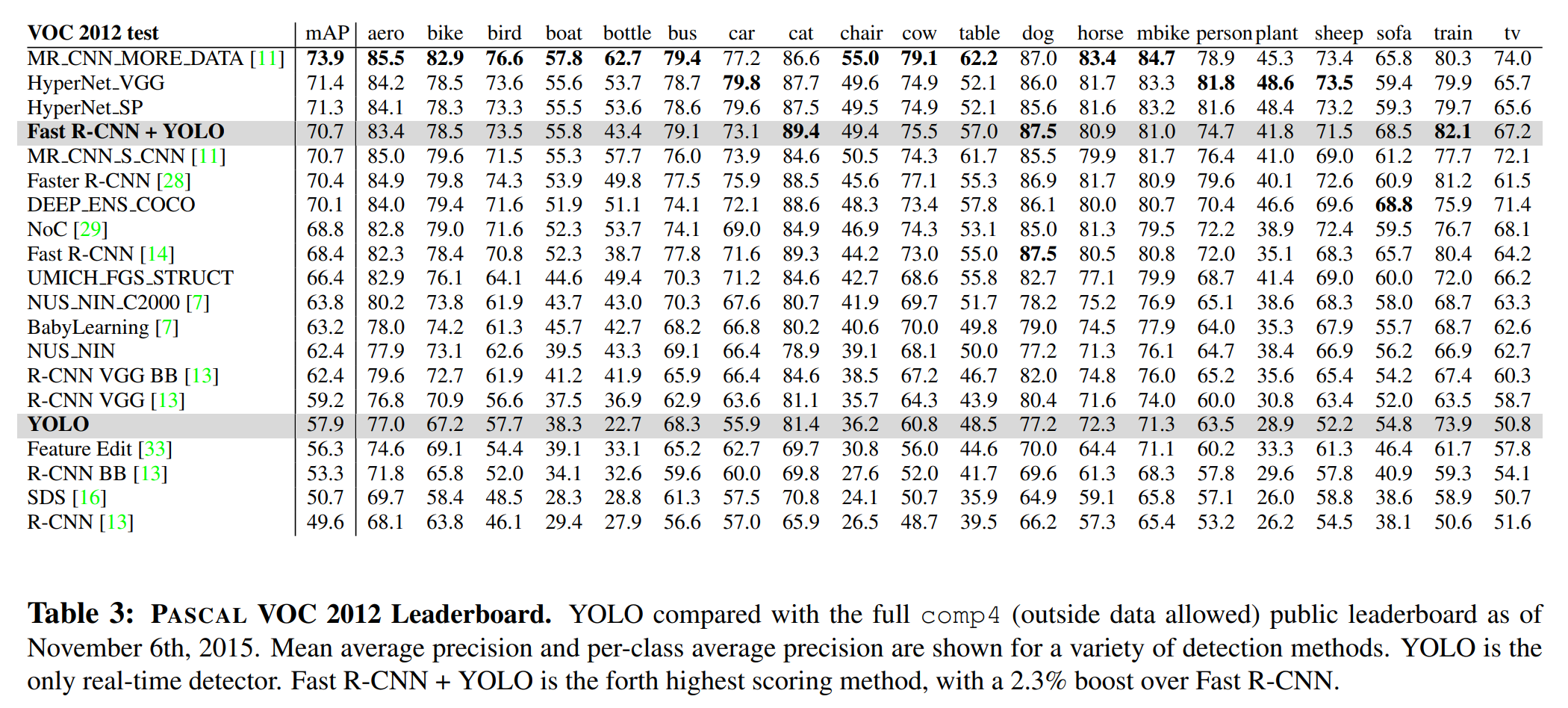
VOC 2012 Test Dataset에 대해서 YOLO는 57.9% mAP를 달성하였고, SOTA보다는 낮은 성능을 보인다. 크기가 작은 물체를 찾는 것을 어려워하고, 특정 Category에 대해서는 성능이 높지만, 어떤 Category에 대해서는 낮은 성능을 보인다. YOLO와 Fast R-CNN을 합친 모델은 상위권의 성능을 보였다.
5. Generalizability: Person Detection in Artwork
우리는 대부분 세상에 존재하는 모든 경우의 Data에 대해 학습할 수 없다. 그렇기 때문에 모델들은 이전에 보았던 사진들에 대해 수렴하도록 학습하는 것이 일반적이다. Picasso Dataset과 People-Art Dataset과 같은 Artwork Dataset을 이용하여 사람 그림을 Test 사진으로 하여 YOLO 모델이 얼마나 여러 상황에 대해 일반화되었는지 확인하는 실험을 진행하였다.

위의 사진을 통해 확인할 수 있는 것은 YOLO 모델이 다른 Object Detection 모델보다 높은 성능을 보인다는 것이다. R-CNN의 경우 artwork로 가게 되면 성능이 갑자기 떨어지게 되는데, 이는 Selective Search가 실제 이미지에서 영역을 뽑도록 만들어졌기 때문이라고 말한다. DPM 모델의 경우 성능이 조금밖에 떨어지지 않은 것을 확인할 수 있는데, 이는 DPM이 Object의 Layout과 Shape을 잘 찾는 모델이기 때문이라고 말한다. 이 뜻은 YOLO 모델도 마찬가지로 Object의 크기와 모양들을 잘 학습한다는 것을 알 수 있다.
5. Real-Time Detection In The Wild
YOLO는 빠르고 정확한 Object Detector이다. 이 모델은 Real-Time의 성능을 보이기 때문에 Webcam을 연결하는 등 여러 곳에 활용될 수 있다. YOLO는 사진을 하나씩 개별적으로 처리하기 때문에 모델을 사용하면 Object를 Tracking 하는 효과를 줄 수 있다.
6. Conclusion
본 논문에서는 YOLO라는 모델을 소개하였고, Object Detection을 하나의 모델로 통합한 모델이다. Classifier를 따로 사용하지 않기 때문에 학습을 한 번에 진행할 수 있고, 이미지 전체에 대해 학습할 수 있다. Fast YOLO의 경우 Object Detection 분야에서 가장 빠른 모델이고, YOLO는 새로운 도메인에 Generalization이 잘 되는 모델이다.
YOLO는 이후에 여러 버전들이 나오게 된다. 그렇기 때문에 필수적으로 알아야 할 논문이다. R-CNN, YOLO, SSD는 Computer Vision 분야를 한다면 꼭 알아야 할 모델이기에 제대로 배우는 것이 좋다.
'Paper Review' 카테고리의 다른 글
| [논문 리뷰] AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving (0) | 2025.03.02 |
|---|---|
| [논문 리뷰] BaM (0) | 2024.12.09 |
| [논문 리뷰] Faster R-CNN (1) | 2022.09.02 |
| [논문 리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2022.08.22 |
| [논문 리뷰] ResNet (0) | 2022.08.15 |




댓글